投稿日:2020年10月14日
文字起こしとは、音源をテキストデータに変換することで、テープ起こしとも言ったりします。
先日のブログ Amazon Polly オススメの音声変換サービス では、テキストデータから音声を作成(Text-To-Speech)しましたが、その逆(Speech-to-Text)のことです。
Word Campでも紹介されている UDトーク もオススメですが、今回はAWSサービスの一つ Amazon Transcribe をご紹介します。
※UDトークはリアルタイムでのテキスト起こしができますが、残念ながら、Amazon Transcribeはできません。
音声データが必要になります。
▲Amazon Transcribe のトップページ。
右上のコンソールにサインインをクリックします。
▲ルートユーザーでログインします。
ユーザー登録がお済みで無い場合、こちらからAWSアカウントの作成 をお願いします。
Amazon Transcribで使用する音声データはあらかじめAWS S3 にアップしておく必要があります。
まずは、その手順をお伝えします。
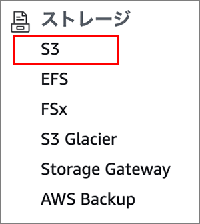
▲AWS マネジメントコンソール にアクセスし ストレージ > S3 をクリックします。
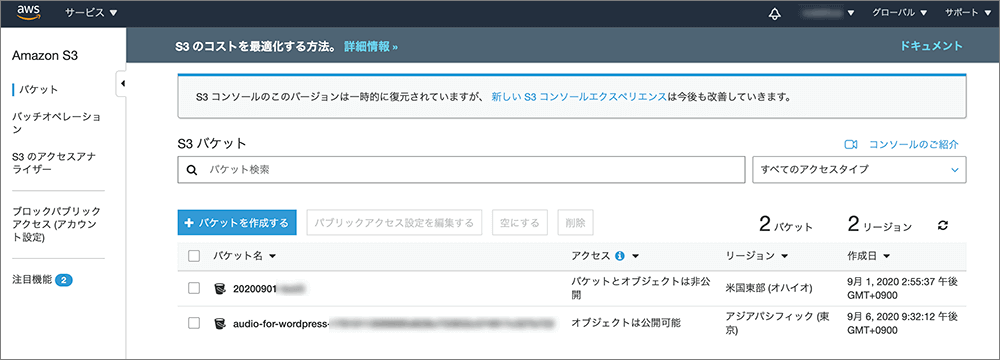
▲Amazon S3 のトップページが開くので、 +バケットを作成する をクリックします。
バケットとはファイルを入れておくための入れ物のことです。
bucket は日本語だとバケツになります。
すでに作成されている場合は下に表示されます。

▲バケットの作成画面が開きます。
バケット名に任意入力。リージョンは アジアパシフィック(東京) を選択します。
既存のバケットから設定をコピー を選択すると、下図のように表示されるので既存のものを選択します。
▲既存のバケットから選択します。
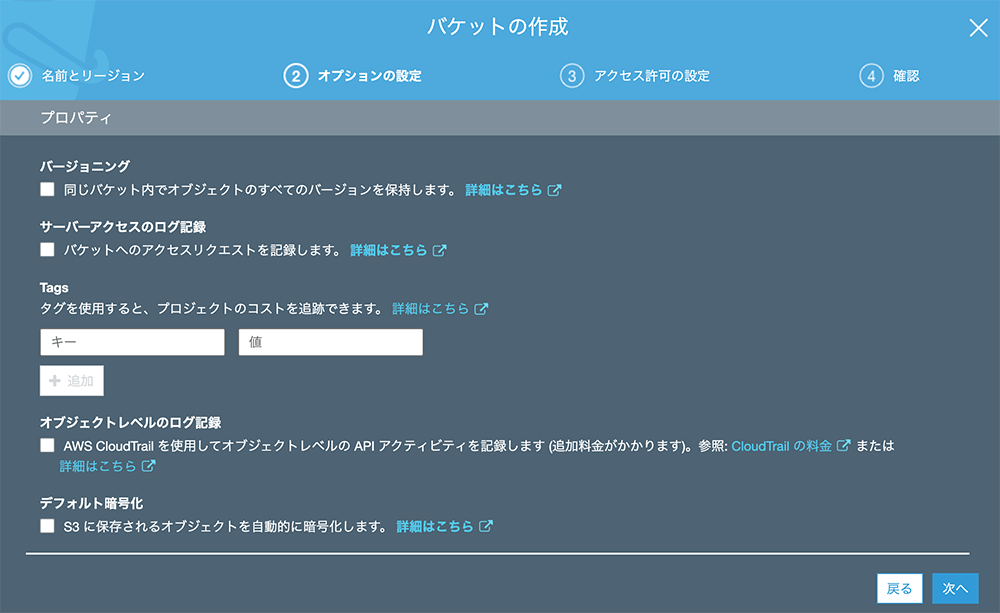
▲色々と設定できますが、今回は上図の設定で進行します。
右下の 次へ をクリックします。
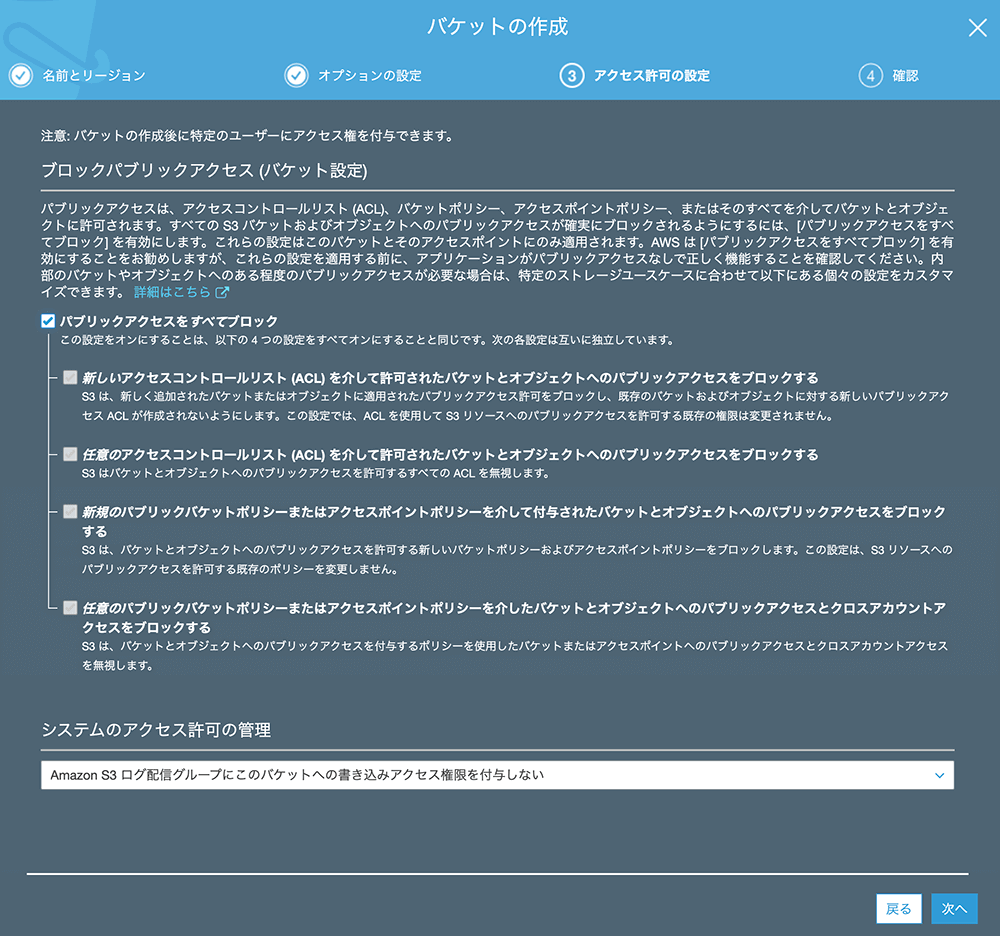
▲アクセス権に関する設定を行います。
今回は上図の設定で進行します。
右下の 次へ をクリックします。
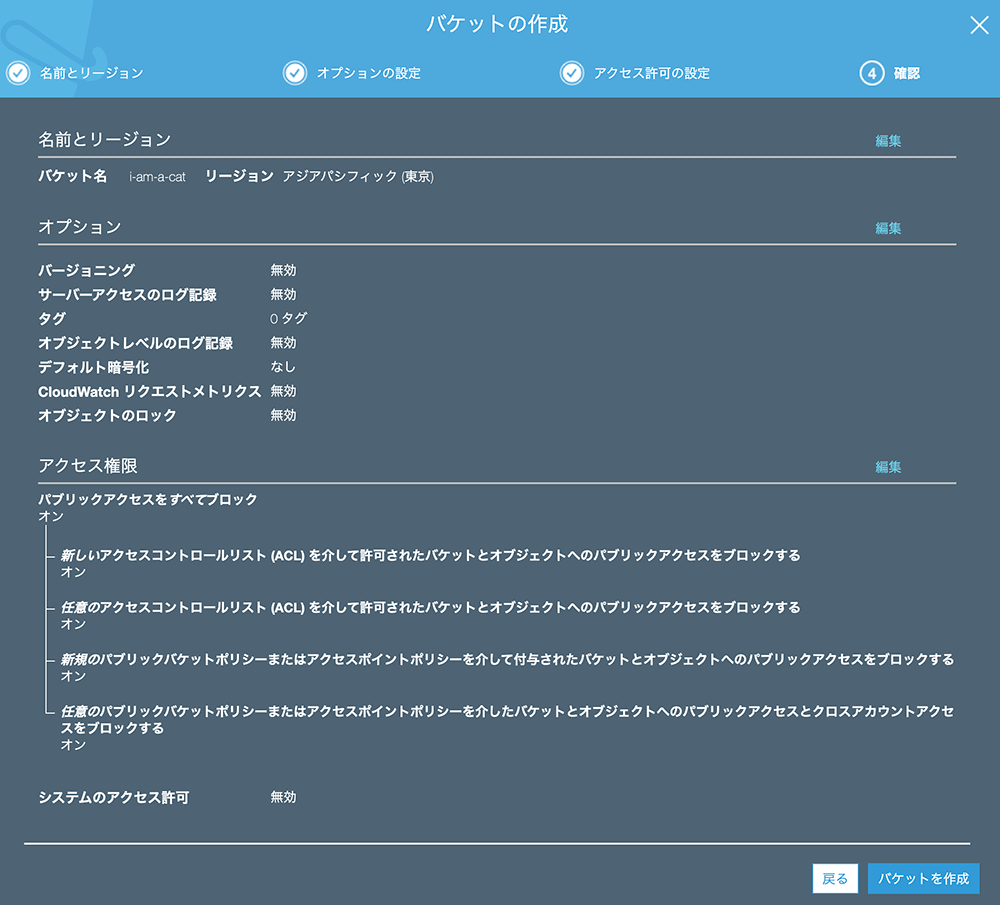
▲確認画面。
右下の バケットを作成 をクリックします。
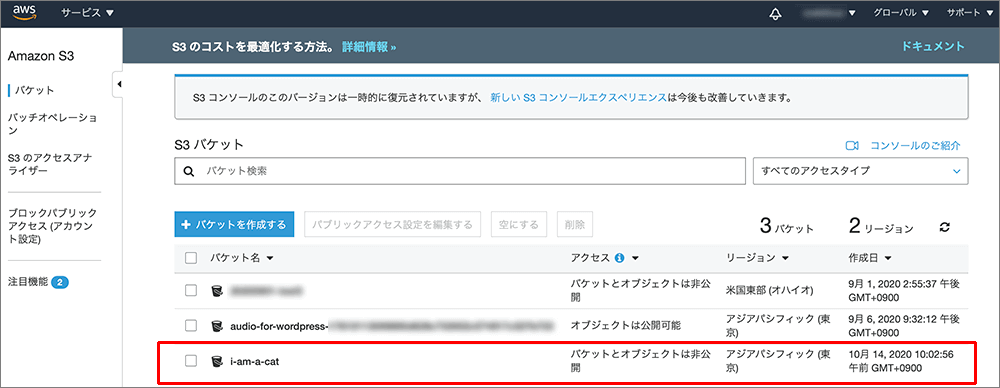
▲バケットが作成されました。

▲確かにバケツの形をしています。
バケット名をクリックします。
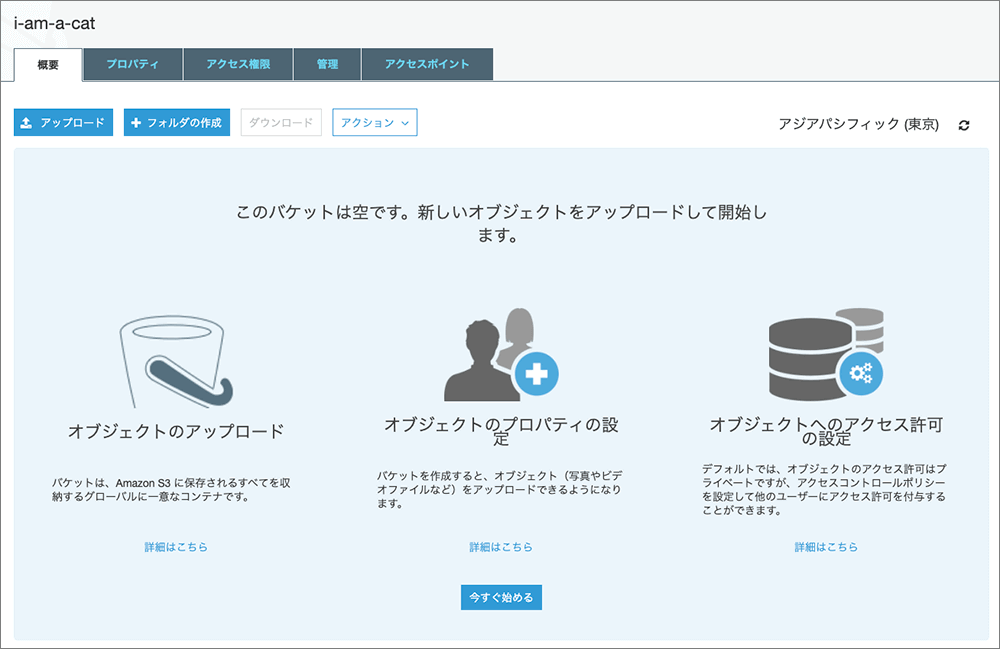
▲バケットに対する処理を行います。
アップロードをクリックします。
▲アップロードするファイルを選択します。
今回は、前回 Amazon Polly で作成した「吾輩は猫である」の音源ファイルを使用します。
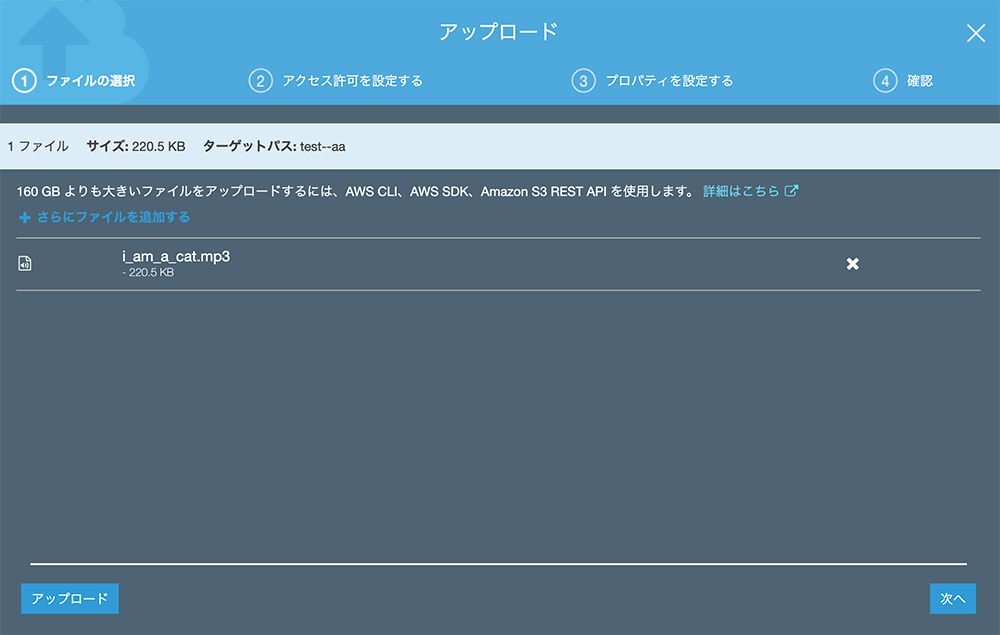
▲ファイルを選択すると上図のような画面になります。
左下の アップロード をクリックすると簡易アップロードができます。
右下の 次へ をクリックすると詳細設定を行いながらのアップロードになります。
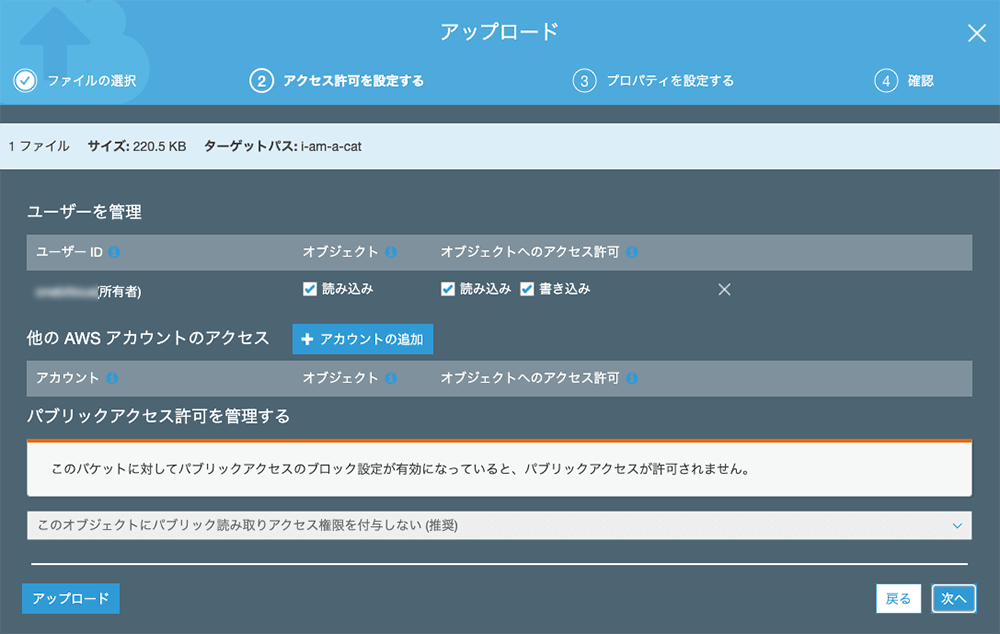
▲前の画面で 次へ をクリックしました。詳細設定の画面です。ファイルへのアクセスに関する設定のようです。
今回は上図の設定で進行します。
次へ をクリックします。
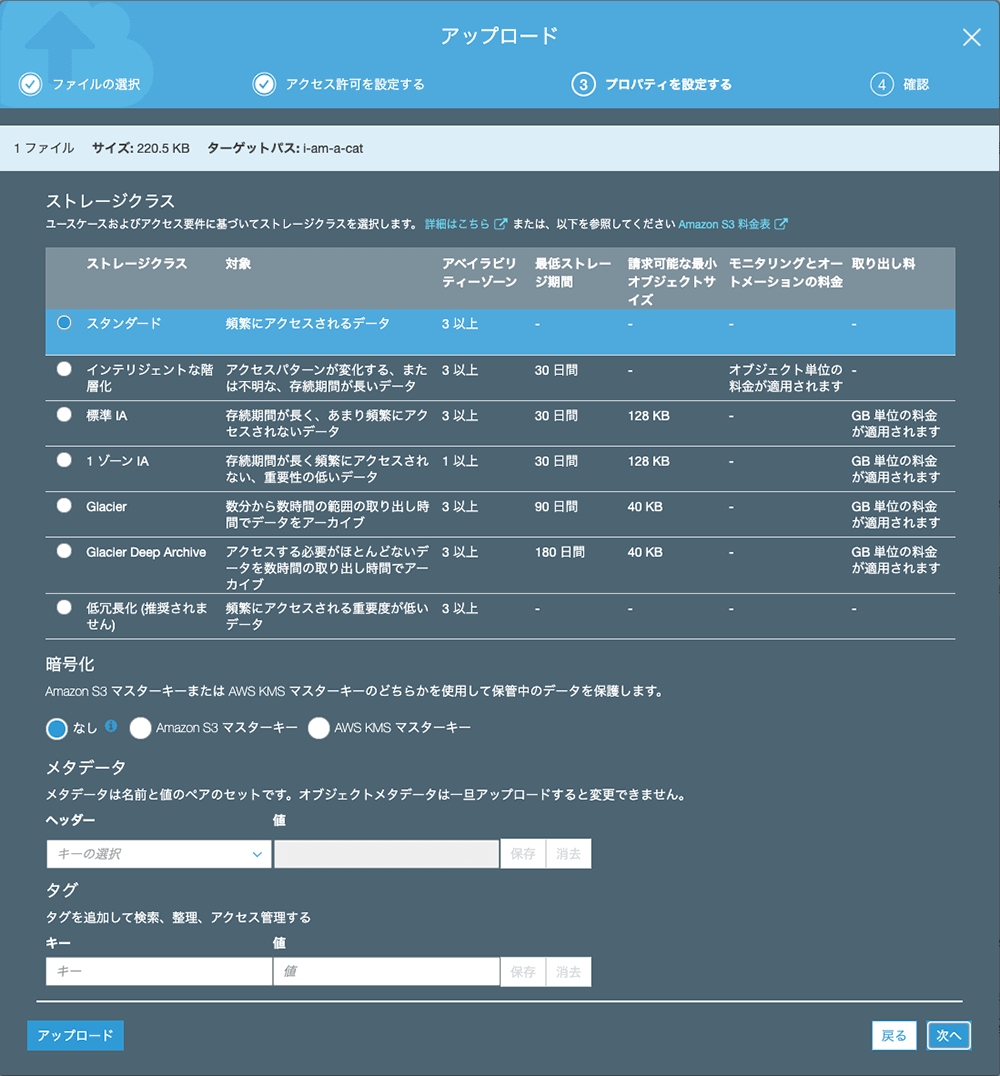
▲ストレージクラスの設定です。
保存期間と容量に関する設定のようで、場合によっては料金がかかるようです。
今回は上図の設定で進行します。
次へ をクリックします。

▲最後に確認画面が開くので右下の アップロード をクリックします。
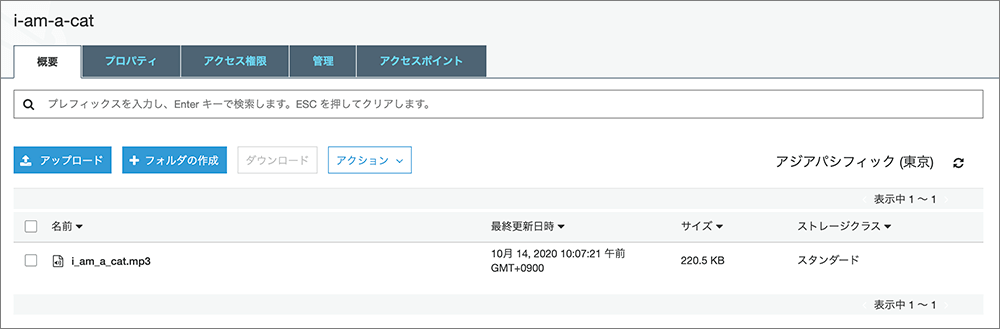
▲これで S3 へのアップロードが完了です。
ここからが Amazon Transcribe の説明です。

▲AWS マネジメントコンソール にアクセスし Machine Learning > Amazon Transcribe をクリックします。
▲Amazon Transcribe のトップページです。
右上の Create job をクリックします。
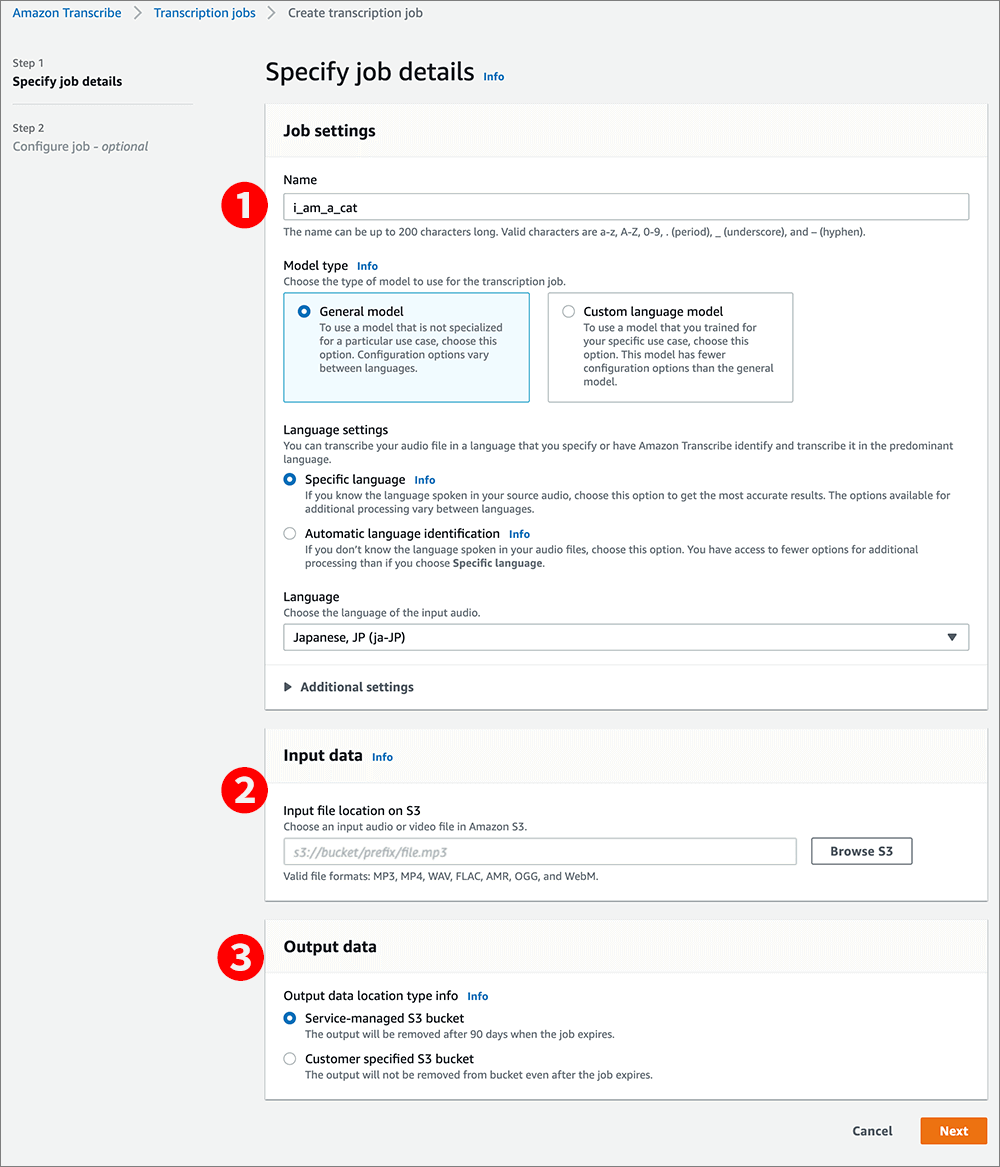
▲❶ひとまず、任意ジョブ名を入力します。
❷先ほどS3にアップロードした音源ファイルを選択します。
Browse S3 をクリックし任意ファイルを選択します。
❸Service-managed S3 bucketは、サービス管理のS3バケットに保存されます。90日後に削除されます。
Customer specified S3 bucketだと、こちらで指定したS3に保存されるのでジョブの期限が切れても削除されません。
上図を翻訳した画面はこちらです。
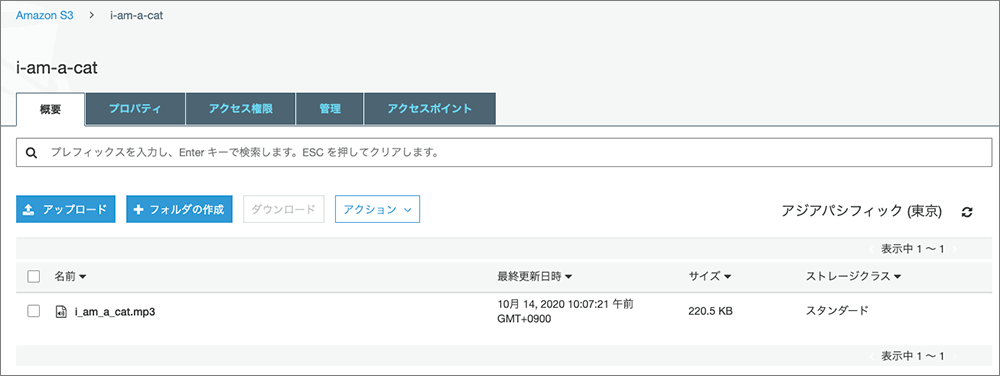
▲❷で任意バケットを選択します。
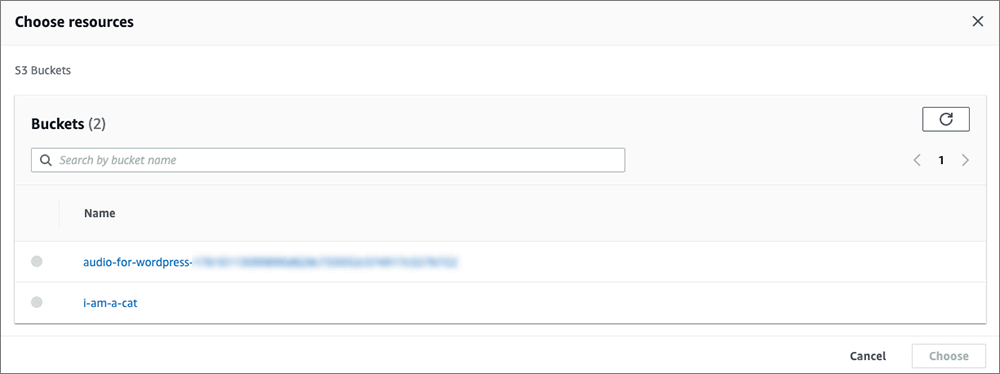
▲さらにバケット内のファイルを選択します。
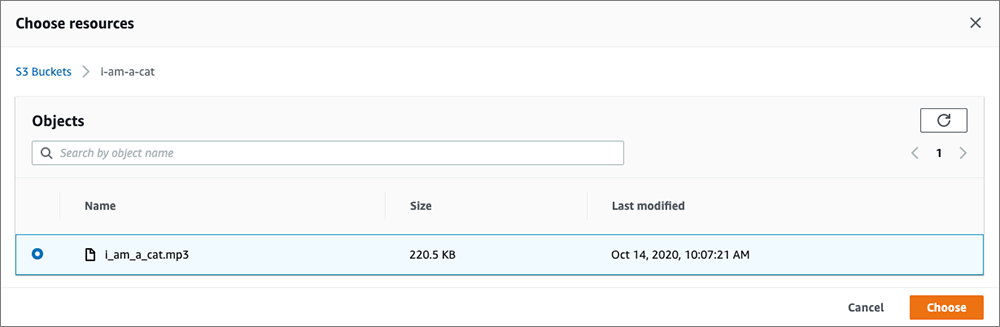
▲最後に右下の Choose をクリックします。
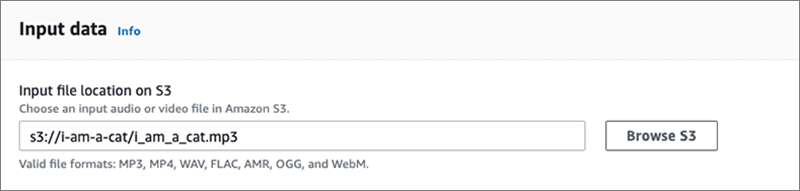
▲先ほどの❸に選択したファイルが表示されます。
▲各設定が済んだら、最初のSpecify job details 画面右下の Next をクリックすると上図が表示されるのでCreate をクリックします。
上図を翻訳した画面はこちらです。
▲しばらく処理中になります。
▲ジョブ作成が完了しました。
ジョブ名をクリックすると下図が開きます。
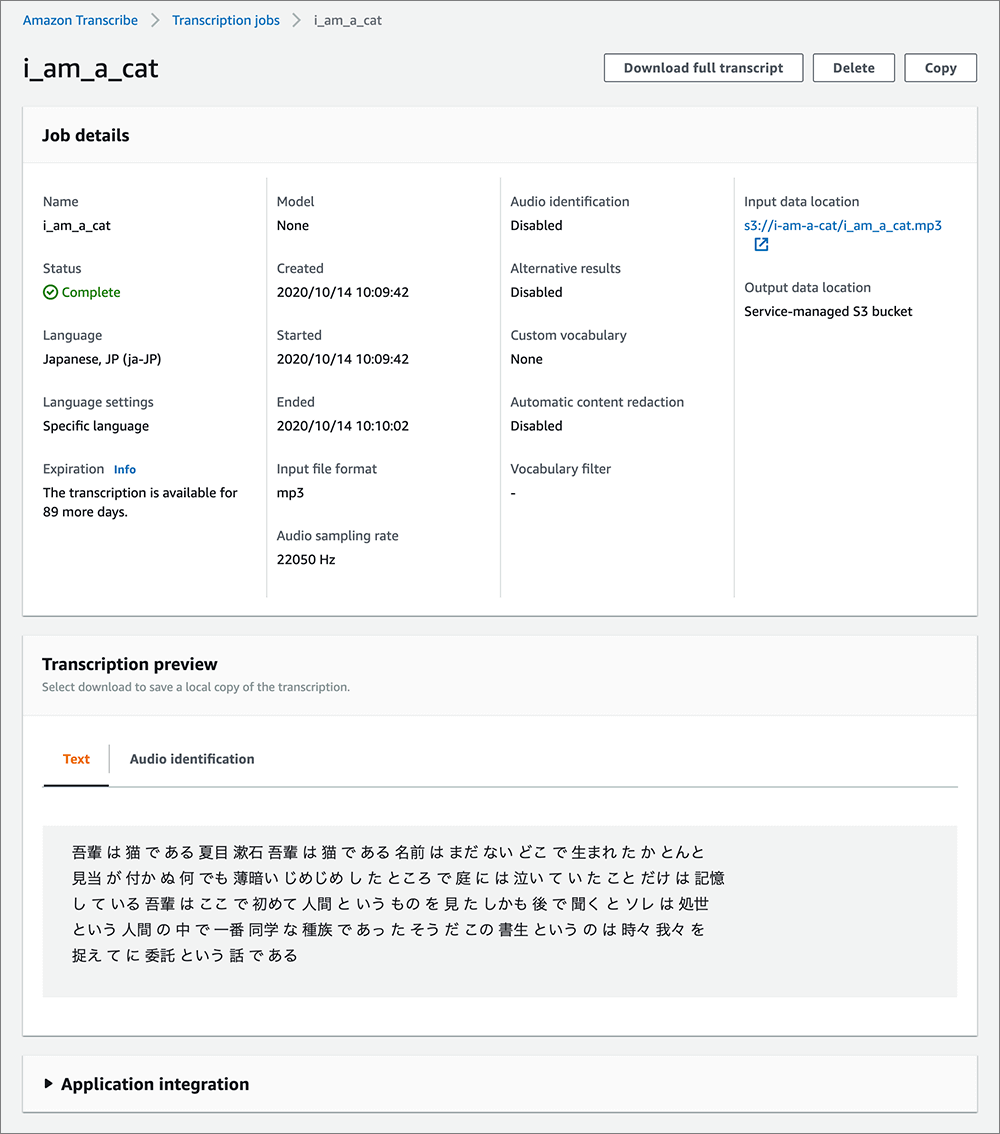
▲詳細、変換後のテキストが確認できます。
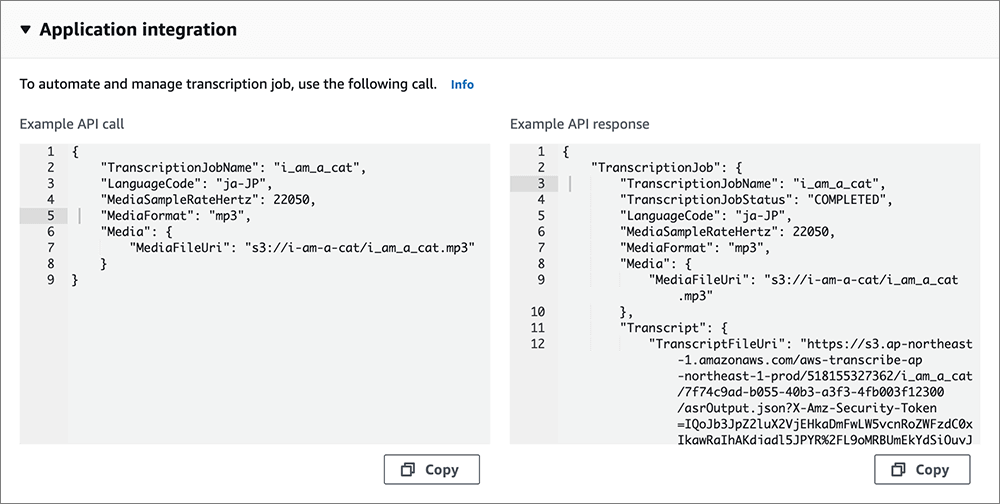
▲最下部の Application integration を表示させた状態。
他のサービスと連携するときのAPIがJSON形式でコピーできます。
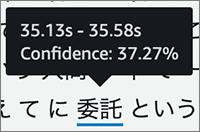
▼変換後テキストの各文字にカーソルを合わせると再生時間と再現の信頼性の割合が表示されます。確かに誤変換した文字は割合が低いですね。


吾輩 は 猫 で ある 夏目 漱石 吾輩 は 猫 で ある 名前 は まだ ない どこ で 生まれ た か とんと 見当 が 付か ぬ 何 でも 薄暗い じめじめ し た ところ で 庭 に は 泣い て い た こと だけ は 記憶 し て いる 吾輩 は ここ で 初めて 人間 と いう もの を 見 た しかも 後 で 聞く と ソレ は 処世 という 人間 の 中 で 一番 同学 な 種族 で あっ た そう だ この 書生 という の は 時々 我々 を 捉え て に 委託 という 話 で ある
▲最後に、音源と変換したテキストを載せておきます。
今回の結果からですと、精度を上げるには、よほど良い発音でないと期待できません。
機械学習とはいえ、100%の再現性は不可能なので、まだまだ人力は必要ですね。。。
リアルタイムでの変換に未対応とのことなので、今後、この辺は頑張って欲しいところです。
原稿執筆の仕事や、セミナーなどのレポート作成、インタビュー記事作成などに活用できそうです。
最後に、気になるお値段ですが、こちらをご参照ください。
最後まで読んでいただきありがとうございました。






