投稿日:2021年11月18日
以前、AWSのAmazon Pollyを検証した記事 を書きました。
Amazon Pollyの日本語音声は、Takumi(男)とMizuki(女)の2つが用意されています。
ニューラルTTS(NTTS)(標準の音声よりも高品質の音声を生成できるシステム)には対応していません。
なので、より高音質な音声を得たい場合、SSML(音声合成マークアップ言語)を使用し、発音やアクセントを調整する必要があります。
使用する音声が大量にあると、処理が大変になります。
それに比べ、Google Text-To-Speechには、ニューラルTTSに対応した日本語が4種類ほど準備されています。
今回はGoogle Text-To-Speechを考察してみます。
始めに聴き比べてみましょう。
共にSSMLは使用せずプレーンテキストで音声化しています。
▲AWS Amazon Polly Takumi スタンダード
▲Google Text-To-Speech ja-JP-Wavenet-D ニューラル
あきらかにニューラルを使用しているGoogleの方が自然に聴こえますね。
Google Text-To-Speechの使用方法です。
今回は、クイックスタートのコマンドラインの使用 を参考に進めます。
手順はおおまかに、環境構築と音声作成の2つに分けられます。
環境構築
▲Googleのアカウントを持っていることが必要条件になります。
作成したらGoogle Cloud にアクセスし、無料で開始、ログインしている場合はコンソールへ移動をクリックします。
▲ダッシュボードへアクセスするとプロジェクトを作る旨が表示されるので作成します。
右のプロジェクトを作成をクリックします。
▲プロジェクト名を入力し作成をクリックします。
▲プロジェクトが作成されました。
左上のハンバーガーメニューをクリックします。
▲課金を有効にする必要があるのでお支払いを設定します。
▲すでに設定済みの場合は上図のように表示されます。
未設定だったらガイドに従って設定しましょう。
▲Text-To-Speech APIを有効にする必要があります。
ハンバーガーメニュー > APIとサービス > ダッシュボード を選択します。
▲ダッシュボードが開きました。
上のAPIとサービスの有効化をクリックします。
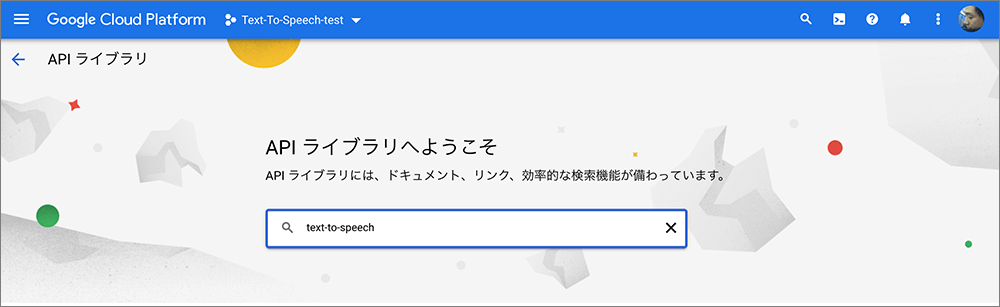
▲text-to-speechを検索します。
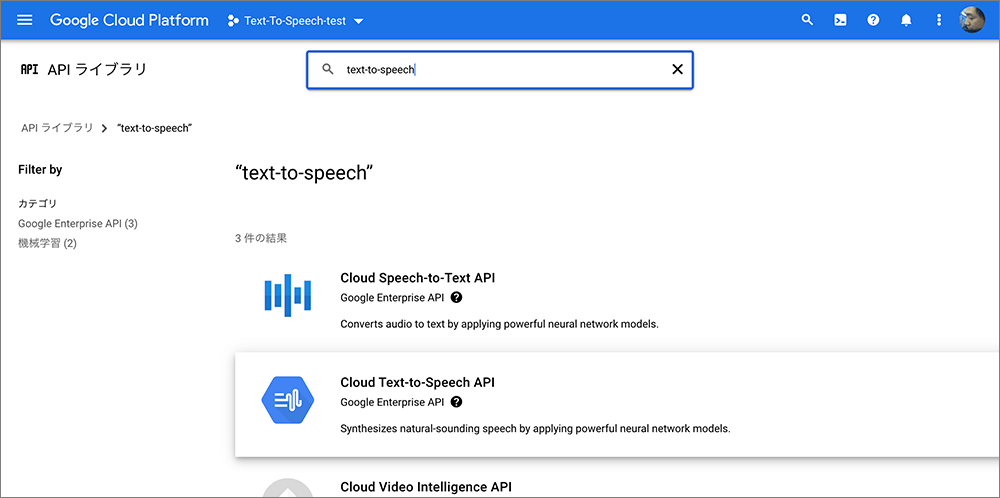
▲検索結果から表示されるCloud Text-To-Speech APIをクリックします。
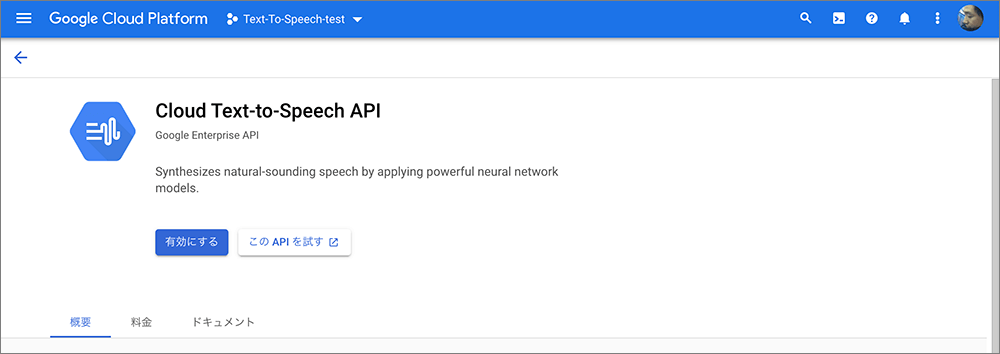
▲有効にするをクリックします。
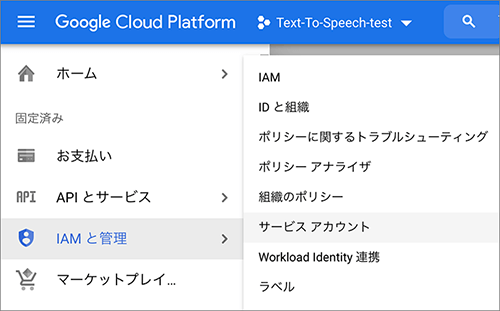
▲続いてサービスアカウントを作成します。
IAMと管理 > サービスアカウント を選択します。
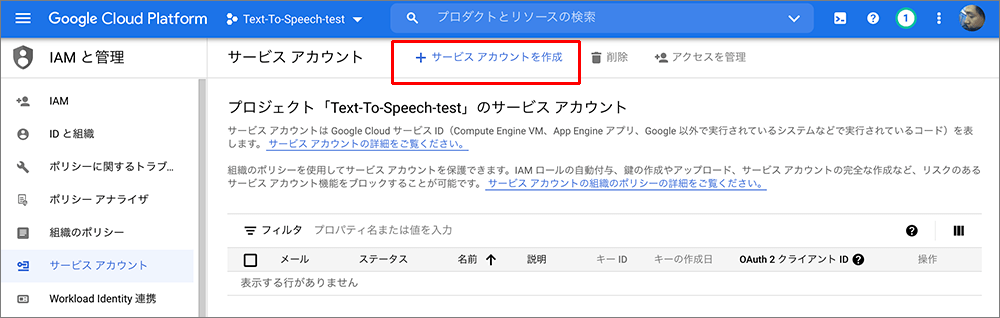
▲上部のサービスアカウントの作成をクリックします。
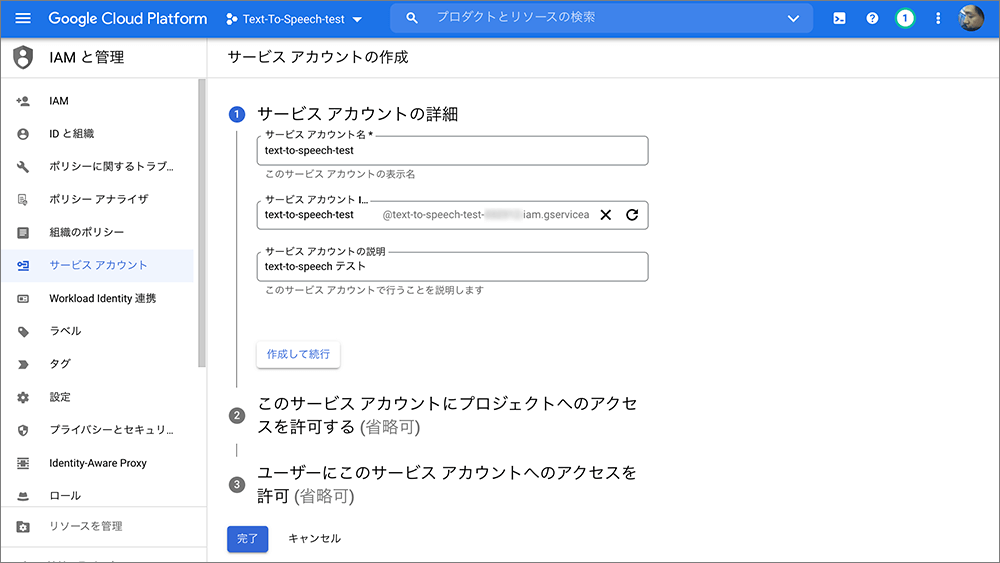
▲サービスアカウント名を入力します。
サービスアカウントの説明は任意で入力します。
作成して続行をクリックします。
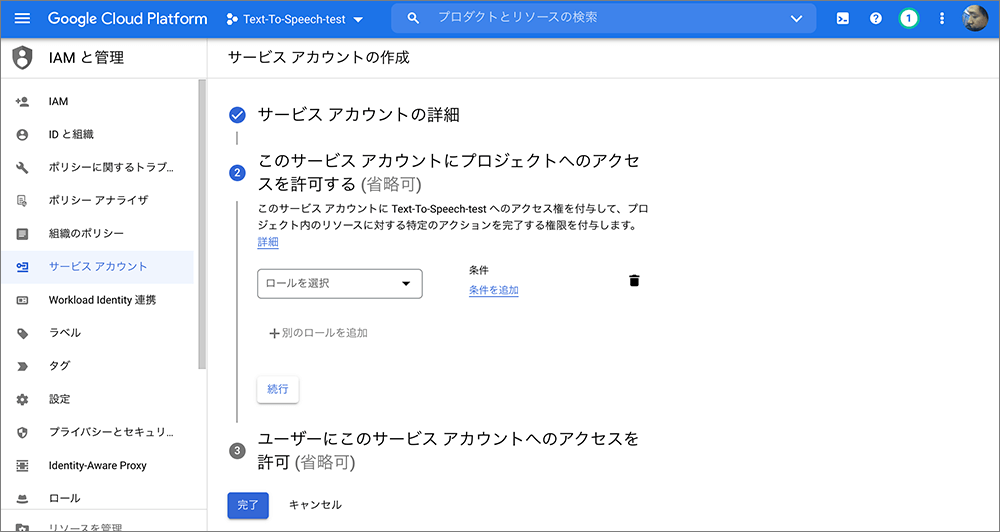
▲表示が変化します。ロールを選択をプルダウンします。
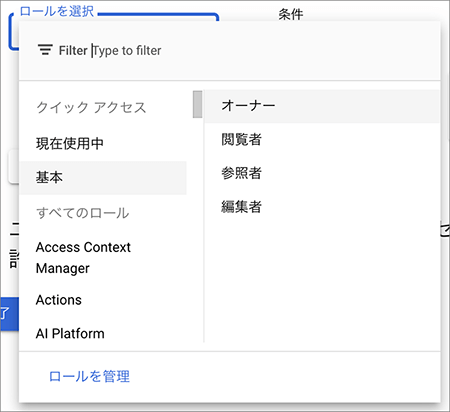
▲ロールを選択をプルダウンし 基本 > オーナー を選択し続行をクリックします。
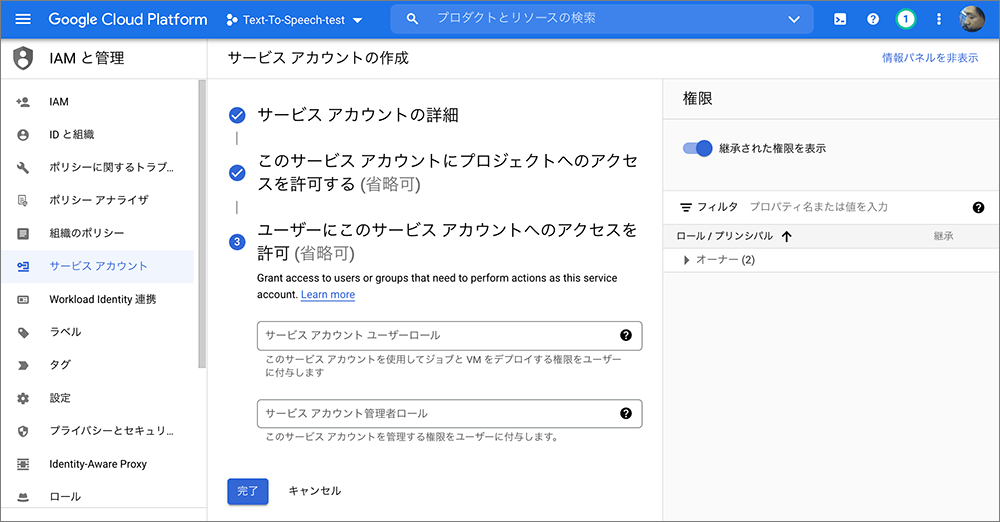
▲この画面はこのままで大丈夫です。
最後に完了をクリックします。
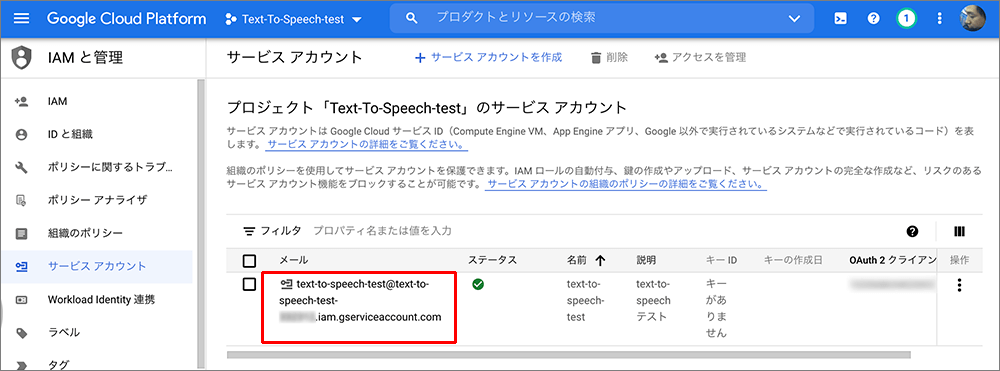
▲サービスアカウントが出来上がりました。
続けて認証キーをダウンロードします。
赤囲みのメールの部分をクリックします。
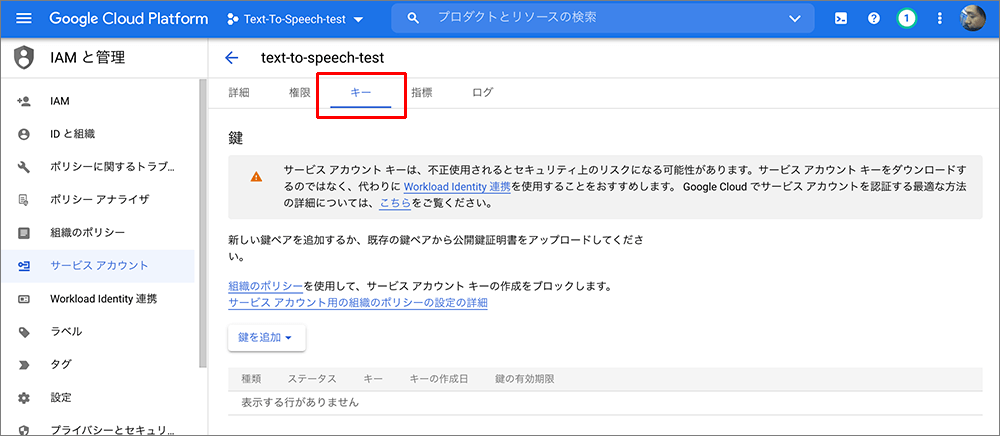
▲メールをクリックするとサービスアカウントの詳細が表示されるので、上部のキータブをクリックします。
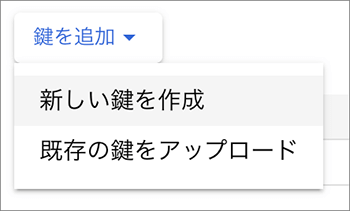
▲鍵を追加をプルダウンし、新しい鍵を作成を選択します。

▲キーのタイプでJSONを選択し作成をクリックします。
▲任意の場所に保存します。
後の作業で色々なファイルを使用するので、フォルダを作って管理するようにしましょう。

▲ダウンロードしたキーファイル。

▲保存完了の旨が表示されるので閉じます。
最後に環境変数GOOGLE_APPLICATION_CREDENTIALSを設定します。
保存したキーファイルのパスを下記のように記載します。
export GOOGLE_APPLICATION_CREDENTIALS="/パス/text-to-speech-test-xxxxxx-xxxxxxaxexxx.json"
ターミナルで下図のように入力します。
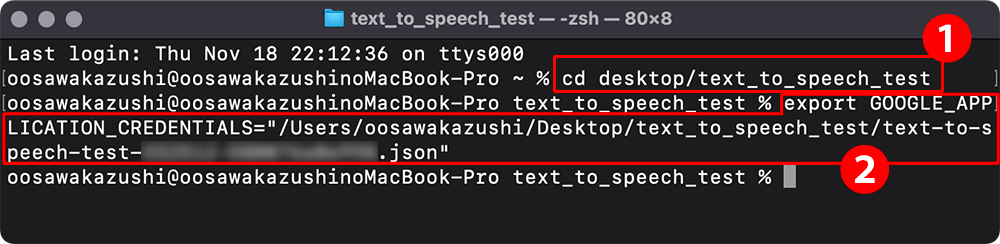
▲❶キーファイルを保存したディレクトリに移動します。
❷環境変数設定のコマンド。
ここまでが環境構築になります。以降も引き続きターミナルを使います。
音声作成
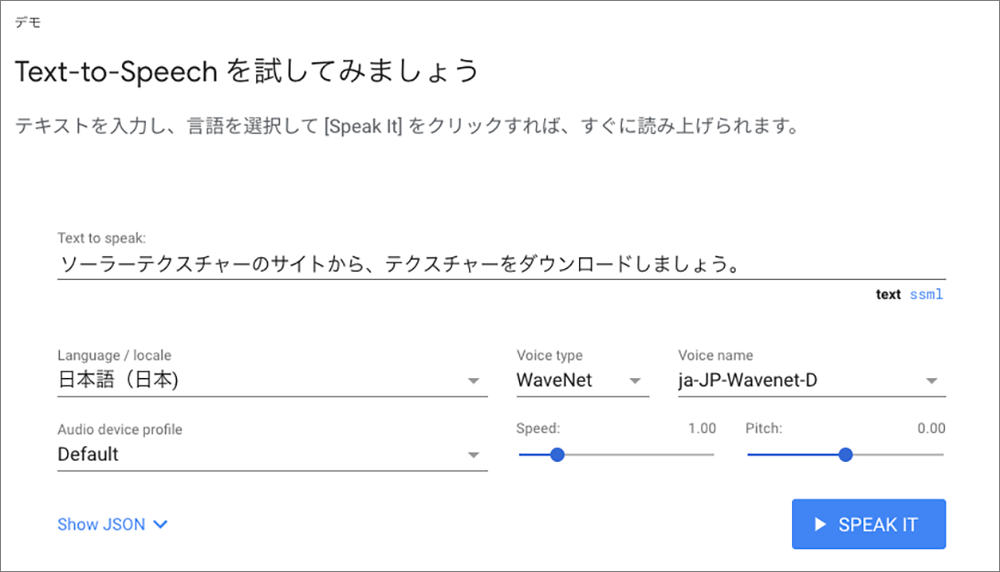
▲Text-To-Speechのトップページ に行きます。
今回は図のように、プレーンテキスト、日本語、ja-JP-Wavenet-Dの設定にします。
設定したら左下のShow JSONをクリックしJSONを展開します。
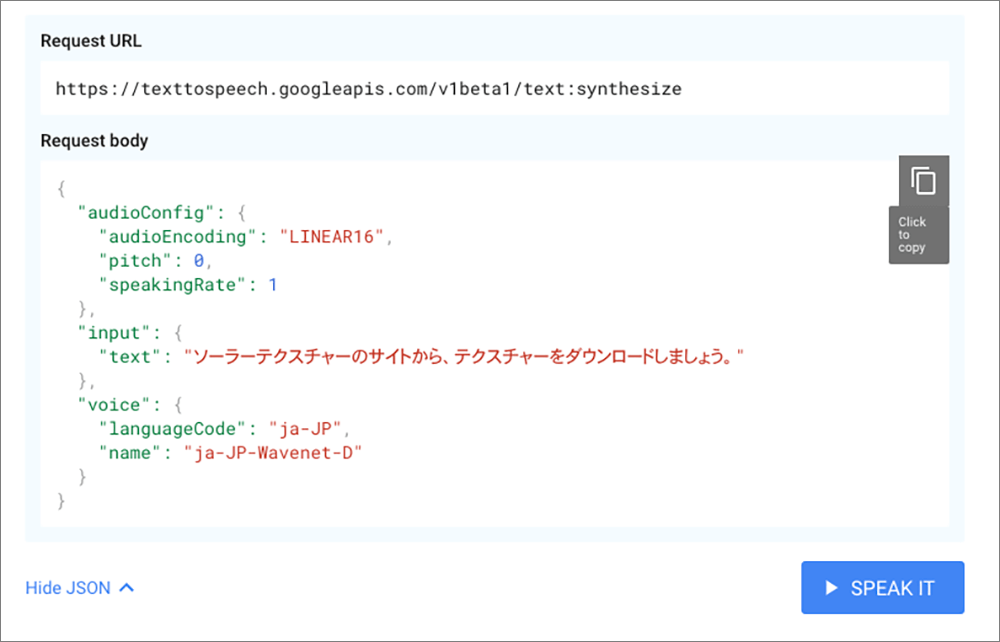
▲JSONが展開されるのでコピーします。
SPEAK ITをクリックするとreCAPTCHAが表示されるのでクリックして再生してみましょう。
コピーしたJSONはrequest.jsonというファイル名で、作成したフォルダに保存しておきます。

▲クイックスタート > コマンドラインの使用 の真ん中くらいに上図のような表示があるのでクリックし展開します。
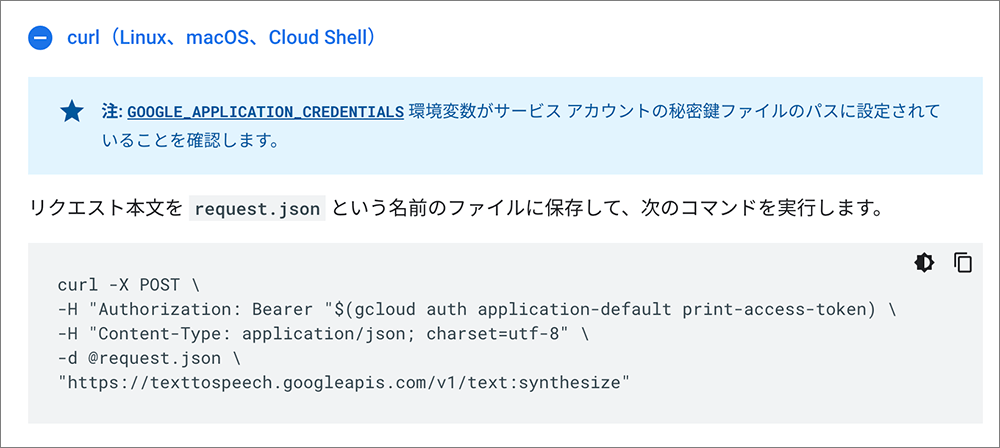
▲展開するとコマンドが表示されます。
先ほどはrequest.jsonというファイル名で保存しましたが、任意のファイル名の場合は、ここを書き換えます。
ターミナルにペーストします。
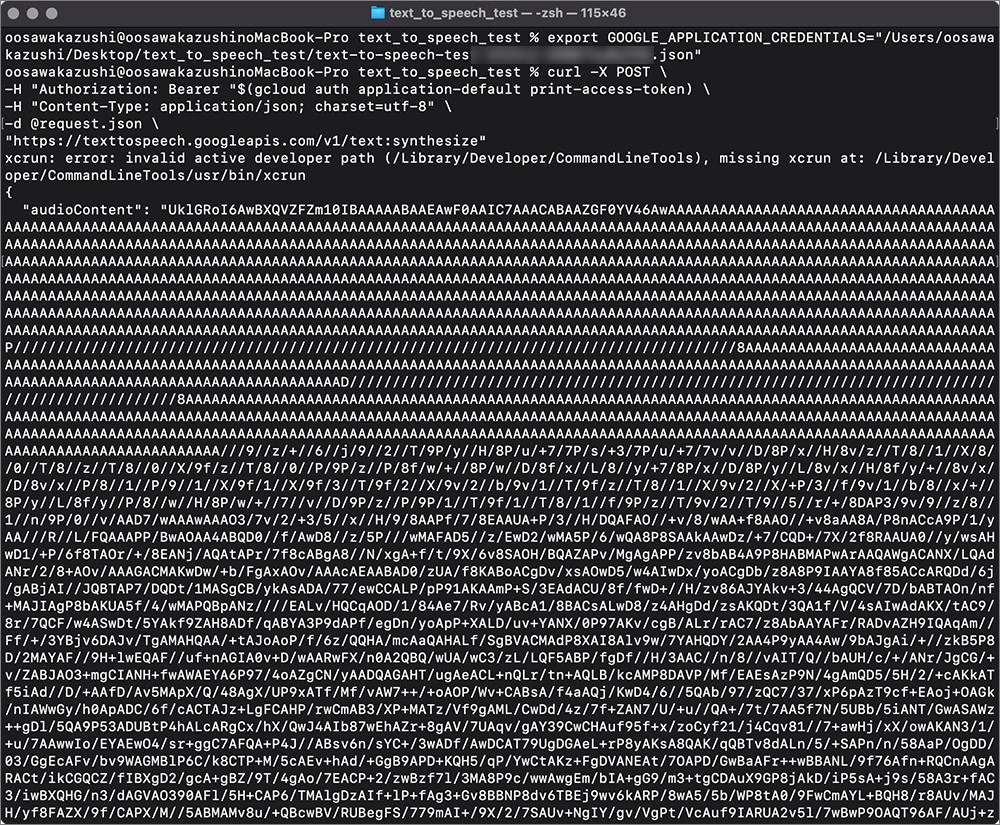
▲base64にエンコードされた形式で出力されます。
{
"audioContent": "UklGRoI6AwBXQVZFZm10IBAAAAABAAE..(略)
}
の箇所が出力結果。
これをコピーして扱うのですが、非常に長文なので非効率的です。
先ほどのコマンドの最終行を下記のようにするとbase64テキストをファイルとして保存することができます。
https://texttospeech.googleapis.com/v1/text:synthesize > output.txt
▲output.txtがファイル名。
{
"audioContent": "UklGRoI6AwBXQVZFZm10...(略)
(略)...///w=="
}
▲出力されたbase64テキスト、output.txtの内容。
略してますが非常に長文です。
これを下のように編集し保存します。
UklGRoI6AwBXQVZFZm10...(略)
(略)...///w==
最後に下記をターミナルに入力します。
base64 --decode output.txt > output.mp3
▲mp3が書き出されました。
これで完了です。
冒頭でも書きましたがニューラルTTSなのである程度の発音、アクセントは高品質なのですが、100%ではありません。
今回は割愛しますがSSMLの詳細はこちらをご参照 ください。
作成例としてGoogle Text-To-Speechを活用した、After Effectsの「皆既月食の作成方法」を掲載しておきます。
最初に聴いたときは、発音の自然さにビックリしました。
ニューラルTTSの恩恵で、今まで、Amazon Pollyで苦労していたSSML付与がかなり軽減されます。
今回紹介した方法とは別にnode.jsを使った組み込みでの使用方法もあるので、機会があったら検証してみたいと思います。
留意事項として、商用利用が可能かGoogleに問い合わせてみたところ、利用規約 を読み、ご自身で判断、もしくは弁護士に相談してくださいとの回答がありました。
この辺は注意する必要があります。
最後まで読んでくださりありがとうございました。




